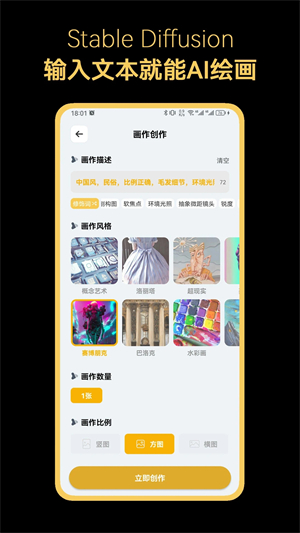
stablediffusion安卓版是一款非常智能的ai图像生成软件,只需要输入中文文本内容,就会帮助用户生成优质的绘画作品,各种风格的绘画作品可以轻松打造出来,在掌握具体的制作流程后,都可以在生成好的绘画作品中,添加不同的滤镜和素材,满足了用户的在线创作需求,生成好的作品可以让用户免费下载,还能够在不同社交媒体中发布。
在机器学习领域,Stable Diffusion是一种经过训练的模型,它可以逐步对随机高斯噪声进行去噪,以获得感兴趣的样本,如生成图像。然而,扩散模型有一个主要的缺点就是去噪过程的时间和内存消耗都非常昂贵,这会使进程变慢,并消耗大量内存。特别是在生成高分辨率图像时,它们在像素空间中运行,这往往是一个瓶颈。
为了解决这一问题,Latent Diffusion引入了一种新的方式,即在较低维度的潜空间上应用扩散过程,而不是使用实际的像素空间来减少内存和计算成本。这个方法被应用在Stable Diffusion中,以解决计算代价昂贵的问题。
Latent Diffusion由三个主要组成部分组成;自动编码器(VAE)、U-Net和文本编码器。VAE由两个主要部分组成:编码器和解码器。编码器将图像转换成低维的潜在表示形式,该表示形式将作为下一个组件U-Net的输入。解码器将做相反的事情,它将把潜在的表示转换回图像。在Latent Diffusion训练过程中,利用编码器获得正向扩散过程中输入图像的潜表示(latent)。而在推理过程中,VAE解码器将把潜信号转换回图像。
U-Net也包括编码器和解码器两部分,两者都由ResNet块组成。编码器将图像表示压缩为低分辨率图像,解码器将低分辨率解码回高分辨率图像。为了防止U-Net在下采样时丢失重要信息,通常在编码器的下采样的ResNet和解码器的上采样ResNet之间添加了捷径的连接。在Stable Diffusion的U-Net中,还添加了交叉注意层对文本嵌入的输出进行调节。交叉注意层被添加到U-Net的编码器和解码器ResNet块之间。这提高了模型对文本信息的理解和利用,使得生成图像更具有可解释性和针对性。
文本编码器将输入的文字提示转换为U-Net可以理解的嵌入空间,它是一个简单的基于transformer的编码器,它将标记序列映射到潜在文本嵌入序列。从这里可以看到,使用良好的文字提示以获得更好的预期输出是非常重要的。
总的来说,Stable Diffusion是一种有效的方法来生成高质量的图像,通过使用Latent Diffusion,可以降低计算成本和内存消耗。这个方法有很好的可扩展性,可以应用于其他领域,如视频生成、自然语言处理等。
1.只要导入自己的照片,就可以快速生成好看的漫画图像。
2.采用了高科技的人工智能技术,能够轻松打造出一幅精美的画作。
3.生成好的作品可以进行二次更改,可以融入自己的个人想法和创意。

1.只需要几分钟的时间就可以生成一幅艺术画,操作起来很简单。
2.软件在使用的过程中会很自由,会帮助用户解决很多的创作难题。
3.在生成对应的绘画作品时,能够启发用户的创作灵感。

在生成绘画作品时不会有次数限制,能让用户多次地生成自己想要的绘画作品,生成记录也会在软件中储存。

欢迎关注我们